Datenbank Autonomie
Oder warum sollten sich mehrere Anwendungen nicht dieselbe Datenbank teilen?

http://www.flickr.com/photos/breville/10731809645/sizes/l/
Viele Köche verderben den Brei: Diseconomy of Scale
Eine gemeinsame Datenbank (geteilt zwischen Anwendungen und/oder Teams) sorgt für unterschiedliche Interessen und erhöhten Absprachebedarf, damit es nicht zu einer Art Wildwuchs kommt.
Wenn keine klaren Schnittstellen definiert sind sinkt die Produktivität aufgrund des erhöhten Kommunikationsaufwandes. Das gilt in Firmen unter Abteilungen und Mitarbeitern, genauso wie für Software-Projekt-Teams als auch für Software selbst.

Bei wenigen Parteien ist die Komplexität oft noch nicht zu sehen.

Desto mehr Parteien es werden, desto komplexer wird es jedoch.
Wikipedia: http://en.wikipedia.org/wiki/Diseconomy_of_scale
“Diseconomies of scale are the forces that cause larger firms and governments to produce goods and services at increased per-unit costs”
Zu Deutsch:
“desto mehr Parteien an einer Sache beteiligt sind, desto höher wird der Kommunikationsaufwand.“
Dazu gibt es auch eine mathematische Formel:
| Workers | Communication Channels |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 3 | 3 |
| 4 | 6 |
| 5 | 10 |
| n |
|
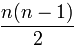
Zur Thematik in der Software-Entwicklung findet man folgende Definition: http://www.softwaremetrics.com/se.htm
“In all software projects there are some basic principles which cause diseconomies of scale. That is:
- Communication becomes difficult as project becomes larger. Multiple logical paths grow in a nonlinear manner as size increases. Interrelationships of functions grow geometrically as project becomes large.
Zu Deutsch:
“In allen Software-Projekten gibt es einfache Gründe, die zur negativen Produktivität führen. Diese sind:
- Kommunikation wird schwieriger, wenn das Projekt größer wird. Wenn ein Projekt größer wird, wachsen die Interessen mit un-linearem Faktor auseinander. Abhängigkeiten von Funktionalitäten steigen im Quadrat wenn das Projekt größer wird.
Dazu findet man beim „Massachusetts Institute of Technology“ (MIT) die folgende These um die Komplexität einzugrenzen: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.350&rep=rep1&type=pdf
„… a manager could choose to divide the project into several smaller projects in order to increase the productivity.“
Zu Deutsch:
“Ein Manager kann sich dazu entscheiden das Projekt in kleinere (unabhängige) Projekte zu teilen, um die Produktivität zu erhöhen.”
IBM schreibt dazu in einem Whitepaper zu Software Economies wie die Ressourcen in einem Software-Projekt zu berechnen sind
ftp://public.dhe.ibm.com/common/ssi/ecm/en/raw14148usen/RAW14148USEN.PDF:
Resources = (Complexity) * (Process) * (Teamwork) * (Tools)
Wobei je 10% weniger beim Vorgänger mehr als 10% mehr Produktivität beim Nachfolger erzeugen.
In diesem Dokument wird auch sehr gut Argumentiert, warum ein Wasserfall-Model (Erst alles Planen und dann erst Bauen, gegenüber einem agilen Ansatz(Kleine Iterationen von Planung und Ausführung zur besseren Kurskorrektur getrieben durch sich mit der Zeit ändernde Anforderungen) im Nachteil ist.
Abstraktion und Muster/Patterns
Die Abstraktion dient in der Software-Entwicklung zur Steigerung der Robustheit gegenüber Änderungen.
Seit (spätestens) 21.10.1994, dem Erscheinungsdatum von „Design-Patterns“ der „Gang of four“ (http://en.wikipedia.org/wiki/Design_Patterns), sollte bekannt sein, dass Abstraktion und lose Koppelung höchste Güter er Software-Entwicklung sind. Als Beispiel dafür der Mediator (http://www.cs.ucsb.edu/~mikec/cs48/misc/Design_Class_Diagrams.htm): Eine Komponente, die zwischen den Anderen steht, um die Komplexität und das Wissen übereinander zu verringern.

Schon in einer einzelnen Anwendung gehört es zu den „best practices“ den Datenzugriff zu abstrahieren
(http://martinfowler.com/eaaCatalog/repository.html) um Änderungen an einer zentralen Stelle zu verwalten und nicht über die gesamte Anwendung ausufern zu lassen.
Direct Data Access vs. Services
Der direkte Zugriff auf eine Datenbank zieht bei einer Änderung des Schemas, also der Datenbank-Strukturen, z.B. hervorgerufen, durch Perfomance-Anforderungen, Geschäftsprozessänderungen oder der Migration auf eine neue oder andere Datenbankversion, Entwicklungsaufwände in JEDER direkt darauf zugreifenden Anwendung nach sich. Dies kann durch Abstraktion des Datenzugriffs und
Autonomie der der Datenbank verhindert werden.
Wikipedia schreibt dazu (http://en.wikipedia.org/wiki/Database_abstraction_layer):
„Database abstraction layers reduce the amount of work by providing a consistent API to the developer and hide the database specifics behind this interface as much as possible“
Zu Deutsch:
“… Abstraktion reduziert die Aufwände durch einen klar definierte Schnittstelle für den Entwickler und versteckt/schützt die Implementierungsdetails so gut wie möglich”
In einem der bekanntesten Portalen der Software-Entwicklung, in dem alle Programmiersprachen diskutiert, und die Antworten allen bewertet werden können findet man den folgenden Eintrag:
http://stackoverflow.com/questions/1530551/direct-acces-database-vs-web-service
“Direct database access couples you tightly to the schema. Any changes on either end affects the other.”
Zu Deutsch:
“Jede Änderung auf einer Seite hat Auswirkungen auf alle anderen”
Und…
„ I would try to go the direct database access route, unless several applications need to share the data…“
Zu Deutsch:
“Ich würde den direkten Datenbankzugriff wählen, es sei denn, mehrere Anwendungen sollen sich die Daten teilen…“
Zu „Entwicklungen“, die über die Zeit eine Datenbank mach und die Vorteile eines zentralisierten Datenzugriffs (http://www.agiledata.org/essays/implementationStrategies.html):
“…a single encapsulation layer … reduce the effort it takes to evolve your database schemas”
Zu Deutsch:
“… ein Einzige Datenzugriffsschicht reduziert die Aufwände die entstehen, wenn eine Datenbank sich weiterentwickelt/wächst”
Globaler Datenzugriff: Die neuen globalen Variablen
Der Einsatz von globalen Variablen ist seit Jahren in der Software-Entwicklung verpönt (http://c2.com/cgi/wiki?GlobalVariablesAreBad). Das liegt daran, dass Code, der mit globalen Variablen arbeitet folgende Eigenschaften mit sich bringt:
- Er verlässt sich darauf, dass eine Variable einen bestimmten Wert enthält. Er lässt sich also nur durch aufsetzen diese Vorbedingungen (Infrastruktur) testen. ABER: Jeder kann den Wert ändern, da ja keiner die Zuständigkeit besitzt (z.B. eine Funktionalität/Service) zu kontrollieren, ob dies zum aktuellen Zeitpunkt auch korrekt ist. Dadurch: Entsteht ein System von Unvorhersehbarkeiten
Eine Datenbank mit „Zugriff für ALLE“ verhält sich genauso. Wie eine globale Variable oder eine Gruppe Kinder zu einem Süßigkeiten-Glas.
Das gilt übrigens technologieübergreifend - auch in JAVA und in allen anderen Programmiersprachen (
http://stackoverflow.com/questions/2867862/service-bus-vs-direct-database-access). Es handelt sich dabei um ein Architektur- bzw. Vorgehens-Problem.
Daten als Dienstleistung
Wenn man sich fragt, was eine Anwendung will, würde man wohl eher sagen, dass sie mit den Daten arbeiten will (z.B. einen Geschäftsprozess abbilden), als, dass sie auf die Datenbank zugreifen will. Das würde sonst schließlich bedeuten, dass die Software zu Selbstzweck oder der Technologie willens existiert. Es ist wie beim Verschicken eines Briefes. Man muss nicht wissen, ob der Briefträger mit dem Fahrrad kommt, zu Fuß unterwegs ist oder mit dem Postauto ausliefert. Es zählt die Dienstleistung!****
Darüber schreibt Wikipedia: http://en.wikipedia.org/wiki/Data_as_a_service
“As the number of bundled software/data packages proliferated and required interaction among one another, another layer of interface was required.”
Zu Deutsch:
“Wenn die Zahl der der Anwendungen/Daten wächst ist eine weitere (Abstraktions-) Schicht nötig”
Service-orientierung
Der Dienstleistungsgedanke ist nicht neu – vor allem nicht in der Software-Entwicklung (siehe Wikipedia http://de.wikipedia.org/wiki/Serviceorientierte_Architektur).
Dabei geht uns nicht um „das große Enterprise“, sondern darum, die IT aus der Perspektive der Geschäftsprozesse und Anforderungen zu sehen. Dabei gilt (für uns) Think big, start small - Nach vorne sehen und sich keine Steine in den Weg von morgen zu legen UND die Aufwände zu jedem Zeitpunkt durch Kontrolle und Steuerung der Komplexität realistisch zu halten und somit agil reagieren zu können.
Mit diesen Gedanken kommt auch ein anderer Blick auf Daten (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.97.8639&rep=rep1&type=pdf):
- Datenzugriff muss koordiniert und kontrolliert werden (Security und Änderungsresistenz) Daten gehören einem Dienst (so wird Kontrolle sichergestellt) Direkter Datenzugriff ermöglicht üblicherweise ein CRUD (Create, Read, Update & Delete – Erstellen, Lesen, Aktualisieren und Löschen) wohingegen ein Dienst die Funktionalität bereitstellt (z.B. „Bestellen“ oder „UmfrageAuswerten“).
Änderungen am Schema und Skalierung
Neben der Tatsache, das sich Geschäftsfelder erweitern und/oder ändern können und sich dadurch Änderungen an den Strukturen in der Datenbank ergeben können, bedeutet es (gerade) für eine (Web-)Plattform, dass wenn sie Erfolg, die Lasten steigen und andere Konzepte nötig werden um die Daten zu speichern und zu lesen. Ein zentralisierter Datenzugriff reduziert die Aufwände in den Anwendungen und ermöglicht Skalierung, Sharding(http://en.wikipedia.org/wiki/Shard_(database_architecture)) und Integrations-Konzepte (http://en.wikipedia.org/wiki/Data_Integration).